KV Cache
1.推理生成的两个阶段
整个推理流程可以分为两个阶段:
**1.prefill阶段(预填充阶段):**该阶段属于计算密集型操作(因为要并行计算大量token得到kv Chache)。模型并行处理输入序列的所有token,生成相应的KV Cache,并输出第一个预测的token。
**2.Decode阶段(解码阶段) :**该阶段属于内存访问密集型操作(只需要用上一个预测的token计算Q,K,V,前文信息用KV Cache,需要大量访存)。以自回归的方式依次生成后续的token。
2.prefill阶段流程
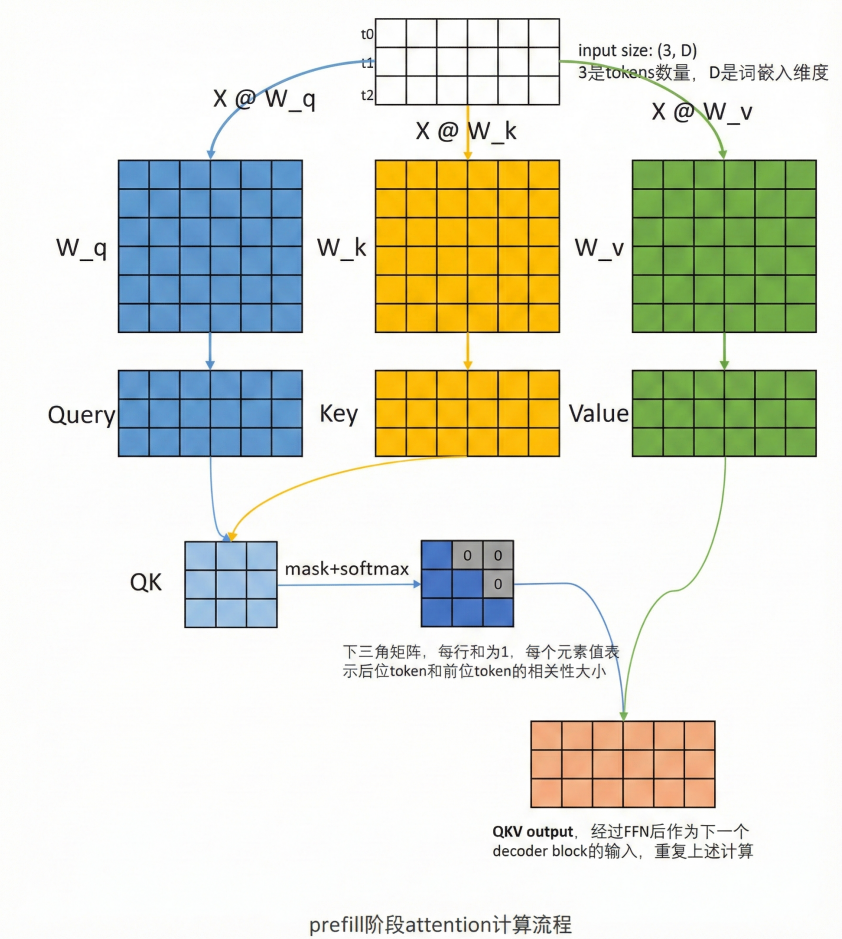
根据全部的token计算,Q,K,V矩阵。最后,再做mask+softmax,得到注意力矩阵,这个矩阵是n*n大小,表示每个token对自己和它之前的token的关注程度,最后和V相乘,相当于做加权求和,得到一个n*dim(dim为隐藏层大小)的上下文向量。
在最后一个decoder block只取QKV output的最后一行,将这一行用线性层处理,映射到vocab大小的维度,并且做softmax,得到logits概率,最大概率的token被选中(greedy算法)
3.Decode�阶段
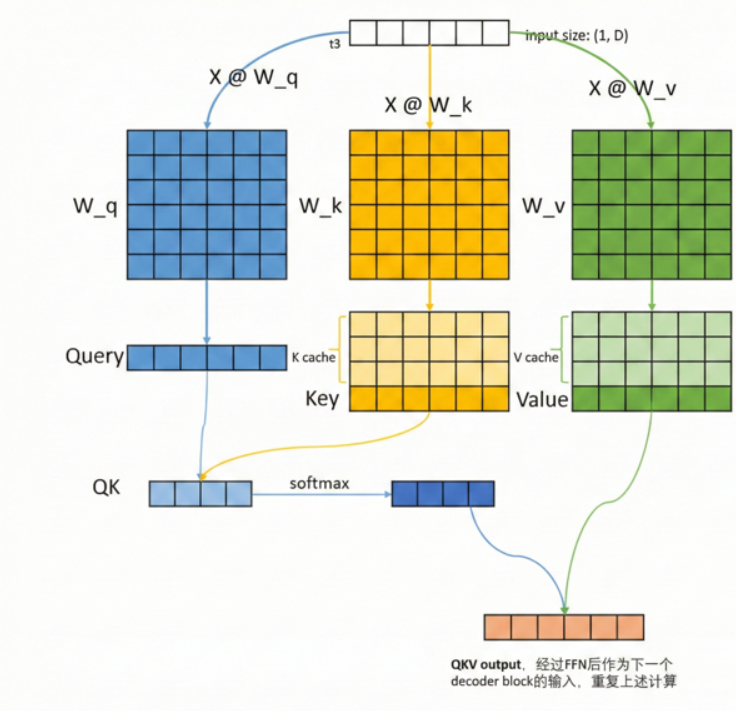
可以看到,t3属于是prefill生成的第一个token,它不需要带上t0-t2再去和W_Q,W_K,W_V做计算,只需要自己与其做计算,再和之前计算好的K矩阵拼接(即K Cache),然后得到一个QK矩阵,该矩阵表示当前token对它以及它之前生成的token的注意力(注意这个矩阵每生成一个token,就会加长),再和矩阵V相乘,同样用到V Cache,得到最终得QKV输出,经过FFN和Add&Norm层处理后,作为下一个decoder block的输入,最后一个输出经过映射到vocab维度,并softmax选取token。
这里笔者开始有两个疑问,解决后在这里记录一下
1.首先为什么有KV Cache,而没有Q Cache
通过计算过程可以发现,在decoder阶段,我们只关心每次最后输出的一个token得到的Q向量分别和K,V矩阵做计算,而并不关心之前已经计算过的token对应的Q向量,因此不需要。
2.为什么没有Q Cache ,但是prefill阶段,每一个decoder block里面都要计算一个完整的Q矩阵,而不是只关注最后一个token对应的Q向量
这个问题其实需要注意,在decoder阶段,每一个decoder block都会用到之前的k v cache,而可以发现,这些k v cache的计算,需要一个完整的QKV output,而若要得到一个完整的QKV output,则Q矩阵必须包含所有token对应的Q向量,即一个完整的Q矩阵,因此预填充阶段,其实也是对k v cache的预填充。